AUTOE2E 先像 crawler 一樣打開網頁,抽取頁面上可執行的 actions。 論文指出探索策略使用 BFS(Breadth-First Search,廣度優先搜尋), 將 actions 放入 crawling queue 逐層執行。每執行一個 action,都可能產生新的頁面狀態。
把論文公式翻成「測試到底有沒有測到功能」
這個頁面用白話拆解、互動範例與小型計算器,解釋 AUTOE2E 論文裡最重要的公式: 功能覆蓋率、功能推論、動作鏈分數,以及作者如何量化 test 是否有效。
探索頁面
↓
擷取動作
↓
推論功能
↓
產生測試
↓
量化覆蓋
Fig. 2 Framework Overview
AUTOE2E 的功能架構:從探索網頁到產生測試案例
論文 Fig. 2 可以理解成四個連續模組。左邊的探索迴圈負責找頁面與 actions; 中間用 LLM 從 screenshot、metadata 和 action context 推論功能; 右邊把功能合併、評分、過濾,最後輸出 Selenium E2E test cases。 其中探索迴圈採用 BFS(Breadth-First Search,廣度優先搜尋)策略逐層探索新的頁面狀態。
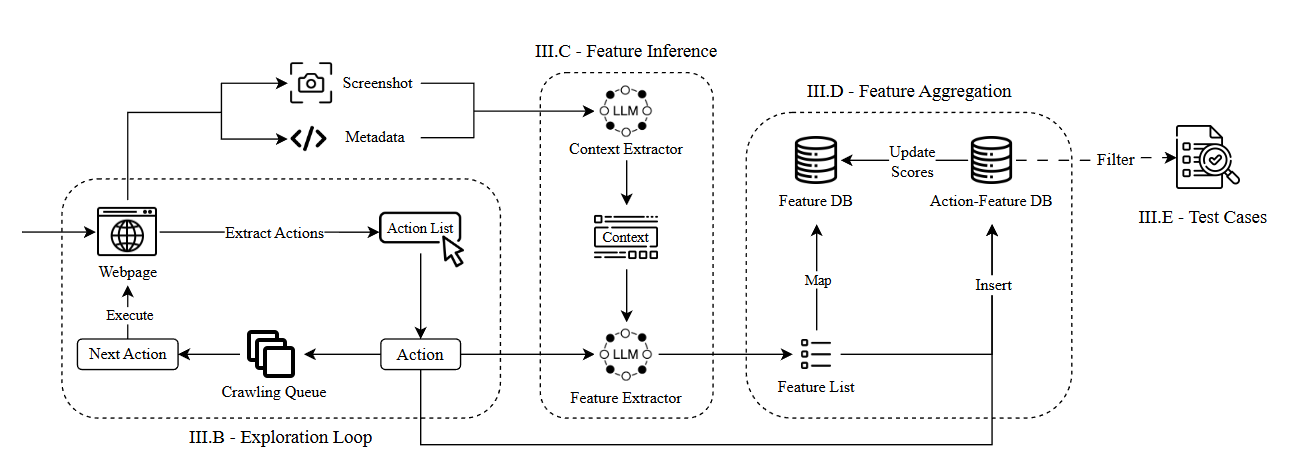
對每個新狀態,系統取 screenshot、metadata,以及導致目前頁面的前一步 action。 LLM 先用這些資訊產生頁面 context,避免只看「Continue」這種模糊按鈕時誤判。
LLM 再根據 context 和目前 action 推論可能功能,例如「搜尋商品」、「查看商品詳情」、 「加入購物車」。這一步對應前面公式中的 \(p(F \mid A_i,A_{i-1})\)。
推論出的功能會先進 Feature DB,用 embedding 找相似功能,再用 LLM 判斷是否為同一功能。 Action-Feature DB 則記錄「哪個 action 支持哪個功能」以及排名分數。
探索結束後,系統依 confidence score 過濾高可信功能,從 AFD 找回對應 action chain, 最後轉成可執行的 Selenium E2E test cases。
III.B Exploration Loop
Webpage
Extract Actions
Action List
Action
Crawling Queue
Next Action
Execute
→
III.C Feature Inference
Screenshot
Metadata
Context Extractor
Context
Feature Extractor
Feature List
→
III.D Feature Aggregation
Map to FD
Feature DB
Insert to AFD
Action-Feature DB
Update Scores
Filter
→
III.E Test Cases
Selected Features
Action Chains
Selenium Tests
Definitions
先看懂兩個核心定義:User Operation 與 Application Feature
論文後面的 Feature Coverage、Feature Inference 和 Test Case Generation 都建立在這兩個定義上。 簡單說,Definition 1 定義「使用者做了什麼」,Definition 2 定義「哪些必要操作合起來才算一個功能」。
Definition 1
使用者操作(User Operation)
使用者操作以 \(U\) 表示,是一串使用者動作 \(\{A_i\}\),例如點擊按鈕、輸入文字、 選取選單或送出表單。論文把 user operation 分成兩類:Entity Operations 和 Configuration Operations。
1. Entity Operations
Entity operation 是對資料實體進行 CRUD 的操作,例如建立、讀取、更新或刪除商品、任務、訂單、bug report。
\[
(X,E,M,P)
\]
- \(X\):CRUD 動作,Create、Read、Update 或 Delete。
- \(E\):目標資料實體或實體集合,例如 Product、Order、Task。
- \(M\):Multiplicity,表示操作影響單一實體或多個實體。
- \(P\):參數集合,例如搜尋關鍵字、商品 ID、篩選條件。
2. Configuration Operations
Configuration operation 是修改系統狀態或設定,例如登入狀態、語言、深色模式、授權狀態。
\[
(C,P)
\]
- \(C\):被修改的設定或組態,例如 Authentication、Language、Theme。
- \(P\):設定的新值,例如 logged in、English、dark mode。
例子:Amazon 搜尋商品怎麼表示?
在 Amazon 裡搜尋商品是一個 Entity Operation,因為它是在讀取 Product 實體集合。
\[
(X=\text{Read}, E=\text{Product}, M=\text{True}, P=\{\text{search term}\})
\]
\(M=\text{True}\) 是因為搜尋通常回傳多個商品;如果是點進單一商品詳情頁, 那就會是讀取單一 Product,\(M=\text{False}\)。
Definition 2
應用功能(Application Feature)
應用功能以 \(F\) 表示。它不是單一 click,而是一串必要的使用者操作,最後造成使用者可見的結果。 這個定義讓 E2E 測試的目標從「點過哪些頁面」提升成「測到哪些真實功能」。
\[
F: U_1 \rightarrow U_2 \rightarrow \cdots \rightarrow U_n
\]
一個功能必須滿足四個條件
- 有限且有序的操作序列: 功能可以透過 \(U_1 \rightarrow U_2 \rightarrow \cdots \rightarrow U_n\) 達成。
- 每一步都是必要的: 移除任何 \(U_i\),功能結果就會改變或無法達成。
- 結果可被使用者看見: 執行完成後會有可見 outcome \(O\),例如購物車數量改變、訂單建立成功。
- 功能標籤是抽象描述: 標籤 \(L\) 不依賴特定參數。搜尋 shoes 或 electronics 都仍然是「搜尋商品」。
例子:加入購物車為什麼是一個 feature?
Amazon 的「加入購物車」不是只有按一次 Add to Cart。它通常包含一串必要操作:
\[
\text{檢視商品列表}
\rightarrow
\text{檢視單一商品詳情}
\rightarrow
\text{建立購物車項目}
\]
如果少了搜尋或瀏覽商品列表,使用者可能找不到商品;如果少了點進商品詳情, 系統可能不知道要加入哪個商品;如果少了建立購物車項目,就沒有完成「加入購物車」。
最後購物車狀態發生可見變化,這就是 outcome \(O\)。
核心重點:Application Feature 是「一串必要操作 + 可見結果 + 抽象功能標籤」。
Feature Coverage
功能覆蓋率:test suite 測到多少應用功能?
\[
C =
\frac{
\left|\{f_j \in F \mid \exists t_i \in T \text{ such that } (t_i, f_j) \in R\}\right|
}{|F|}
\]
白話版
從所有功能 \(F\) 裡面,找出「至少被一個測試案例測到」的功能,然後除以功能總數。 它關心的是使用者功能是否被測到,而不是程式碼跑過幾行。
三個符號
- \(F\):系統所有功能,例如登入、註冊、下單。
- \(T\):所有測試案例。
- \(R\):測試案例和功能的對應關係。
詳解版:一步一步拆這個公式
這個公式在算什麼?
它在算「測試套件實際測到多少應用中應該存在的功能」。所以整體可以先記成:
\[
C = \frac{\text{被測到的功能數量}}{\text{所有功能數量}}
\]
1. 分母:\(|F|\)
\(F=\{f_1,f_2,\ldots,f_m\}\) 是系統所有功能的集合, 所以 \(|F|\) 代表功能總數。
例如 \(F=\{\text{登入},\text{註冊},\text{下單},\text{付款},\text{查訂單}\}\), 那麼 \(|F|=5\)。
2. 分子:被至少一個 test 測到的功能
這段: \[ \{f_j \in F \mid \exists t_i \in T \text{ such that } (t_i,f_j)\in R\} \] 意思是「從所有功能 \(F\) 裡面,挑出至少存在一個測試案例 \(t_i\) 有測到的功能 \(f_j\)」。
- \(\exists t_i \in T\):存在某個測試案例。
- \((t_i,f_j)\in R\):這個測試案例有測到這個功能。
- 外面的 \(|\cdot|\):計算這些被測到的功能有幾個。
3. 完整例子
假設 \(F=\{f_1,f_2,f_3,f_4,f_5\}\), \(T=\{t_1,t_2,t_3\}\),而測試關係是:
\[
R=\{(t_1,f_1),(t_1,f_2),(t_2,f_3),(t_3,f_3)\}
\]
代表 \(t_1\) 測到 \(f_1,f_2\),\(t_2\) 測到 \(f_3\),\(t_3\) 也測到 \(f_3\)。 注意 \(f_3\) 被測兩次仍然只算一個功能。
被覆蓋的功能是 \(\{f_1,f_2,f_3\}\),共有 3 個;所有功能有 5 個,所以:
\[
C=\frac{3}{5}=0.6=60\%
\]
核心重點:只要某個功能至少被一個測試案例測到,就算被覆蓋;重複測到同一功能不會讓分子增加。
Feature Inference
\(p(F \mid S)\):從觀察到的頁面狀態推論功能
\[
p(F_1, F_2, \ldots, F_M \mid S_1, S_2, \ldots, S_K) = p(F \mid S)
\]
白話版
給定一個 web app 被探索到的所有狀態 \(S\),模型要推論這個 app 可能有哪些功能 \(F\)。 例如看到搜尋列、商品列表、加入購物車按鈕,就推論出搜尋商品、查看商品、加入購物車等功能。
論文為什麼簡化?
直接從所有頁面狀態推論全部功能太複雜,所以作者把問題改成以 action 為中心: 看每個頁面上可做的動作,再搭配頁面截圖與前一步動作推論功能。
詳解版:為什麼要寫成 \(p(F \mid S)\)?
這個公式在問什麼?
它問的是:當我們已經觀察到 web app 的一些頁面狀態 \(S\) 後, 哪些功能 \(F\) 最可能真的存在?
用白話講就是:看過這個網站的幾個畫面之後,我們能不能推論它有「搜尋商品」、「加入購物車」、「查看訂單」等功能。
1. 條件機率的意思
\(p(F \mid S)\) 讀作「在給定 \(S\) 的情況下,\(F\) 的機率」。 \(S\) 是觀察到的 evidence,\(F\) 是想推論的功能集合。
2. 為什麼不能直接做?
因為完整頁面狀態太龐大,包含 DOM、文字、圖片、執行時變數、使用者歷史等。 直接從所有狀態推論所有功能,搜尋空間會非常大。
3. 作者的解法
作者後面把它簡化成 action-centric inference:不要看整個 state 的所有細節, 而是看每個狀態中有哪些可執行 action,因為功能通常是透過 action 被觸發的。
核心重點:\(p(F \mid S)\) 是整篇 feature inference 的起點,但實作時作者不直接解它,而是逐步把它改寫成可由 actions 和 LLM 排名估計的分數。
Action Chain
動作鏈:一個功能通常不是一個 click
\[
F : A_1 \rightarrow A_2 \rightarrow \cdots \rightarrow A_N
\]
第一步提供「我要找某個商品」的意圖,後續 action 才能連成加入購物車這個功能。
Action-Centric Inference
把狀態空間簡化成 action 空間
\[
p(F \mid S)
=
p(F \mid A_{1,1}, A_{1,2}, \ldots, A_{K,n_K})
\tag{2}
\]
白話版
原本要從整個頁面狀態 \(S\) 推論功能,但完整 state 太大、太雜。 作者觀察到 web app 的功能通常可以從「頁面上有哪些可執行 action」看出來, 所以把問題改成看所有狀態中的 actions。
符號怎麼看
- \(S_i\):第 \(i\) 個頁面狀態。
- \(A_{i,j}\):狀態 \(S_i\) 上第 \(j\) 個可執行 action。
- \(n_i\):狀態 \(S_i\) 上 action 的數量。
例如商品頁的「Add to Cart」按鈕,比整份 HTML 更直接地暗示「加入購物車」功能存在。
詳解版:為什麼 action 比完整頁面更重要?
1. 原本的問題
原本是 \(p(F \mid S)\):從頁面狀態推論功能。 但 \(S\) 太複雜,HTML 裡有很多和功能無關的東西,例如樣式、排版、廣告、重複元件。
2. 作者的觀察
E2E 功能通常由使用者動作觸發,例如 click、input、submit。 因此,真正能說明功能的是頁面上的可執行 actions。
3. 公式怎麼讀
\[ p(F \mid A_{1,1}, A_{1,2}, \ldots, A_{K,n_K}) \] 代表:給定所有狀態中觀察到的 actions,推論功能 \(F\)。
\(A_{1,1}\) 是第 1 個狀態的第 1 個 action; \(A_{K,n_K}\) 是第 \(K\) 個狀態的第 \(n_K\) 個 action。
核心重點:這一步把「理解整個網站」變成「理解使用者可以做哪些事」,問題小很多,也更貼近 E2E testing。
Bayes + Chain Rule
把一個功能視為一串必要 actions
\[
p(F \mid S)=p(F \mid A_1,A_2,\ldots,A_N)
\]
\[
=
\frac{p(F,A_1,A_2,\ldots,A_N)}
{p(A_1,A_2,\ldots,A_N)}
\]
\[
=
\frac{
p(F)p(A_1 \mid F)p(A_2 \mid A_1,F)\cdots p(A_N \mid A_1,\ldots,F)
}
{p(A_1,A_2,\ldots,A_N)}
\tag{3}
\]
白話版
一個功能 \(F\) 不是孤立出現,而是由 action chain 觸發。 所以作者用 Bayes theorem 和 chain rule,把「這個功能是否存在」拆成 每一步 action 對功能的證據。
例子
「加入購物車」可以看成: \(A_1\) 搜尋商品、\(A_2\) 點選商品、\(A_3\) 按 Add to Cart。 每一步都讓「加入購物車」這個功能更明確。
詳解版:Bayes 和 chain rule 在這裡扮演什麼角色?
1. 先把功能改寫成 action chain
作者先假設一個功能可以由一串必要 actions 表示: \[ F:A_1\rightarrow A_2\rightarrow\cdots\rightarrow A_N \] 所以 \(p(F \mid S)\) 可以改看成 \(p(F \mid A_1,A_2,\ldots,A_N)\)。
2. Bayes theorem
Bayes theorem 把「看到 action chain 後功能存在的機率」改寫成: \[ p(F \mid A_1,\ldots,A_N) = \frac{p(F,A_1,\ldots,A_N)}{p(A_1,\ldots,A_N)} \]
3. Chain rule
接著用 chain rule,把聯合機率 \(p(F,A_1,\ldots,A_N)\) 展開成一連串條件機率: 先有功能 \(F\),再看第一個 action,在第一個 action 之後看第二個 action,以此類推。
4. 例子
對「加入購物車」來說,合理 action chain 是: 搜尋商品 → 點商品 → Add to Cart。 如果這些 actions 依序出現,就能越來越支持「加入購物車」這個功能存在。
核心重點:公式不是為了真的精準算出所有機率,而是為後面「每一步 action 都提供功能存在的證據」建立理論基礎。
Feature Scoring
最後怎麼決定哪個 feature 最可能存在?
\[
p(F)p(A_1 \mid F)=p(A_1)p(F \mid A_1)
\]
\[
p(A_i \mid A_{i-1},F)
=
\frac{
p(F \mid A_i,A_{i-1})p(A_i \mid A_{i-1})
}
{p(F \mid A_{i-1})}
\]
\[
p(F \mid S)
=
\beta(A)p(F \mid A_1)
\prod_{i=2}^{N}
\frac{p(F \mid A_i,A_{i-1})}{p(F \mid A_{i-1})}
\tag{4}
\]
\[
F
=
\arg\max_F
\sum_{i=1}^{N}
\left(
\log p(F \mid A_i,A_{i-1})
-
\log p(F \mid A_{i-1})
\right)
\tag{5}
\]
白話版
作者想找的是:哪個功能 \(F\) 最能解釋目前看到的 action chain。 如果加入新 action 後,某個功能的可信度上升很多,這個功能就會得到更高分。
直覺解讀
只看到「點商品」時,可能有很多功能。看到下一步「Add to Cart」後, 「加入購物車」比「評論商品」更能解釋這串 actions,所以分數上升。
這也是 AUTOE2E 不只是叫 LLM 猜功能,而是用「每一步 action 帶來多少新增證據」來累積分數。
詳解版:最後的 argmax 公式怎麼看?
0. 這張卡其實包含兩步
論文不是直接跳到 \(\arg\max\)。它先從 action chain 的機率式出發, 再利用「後續 action 主要依賴前一步 action 和目標功能」這個假設,把式子整理成可以逐步累積的分數。
1. 先處理第一個 action
第一個轉換式是: \[ p(F)p(A_1 \mid F)=p(A_1)p(F \mid A_1) \] 這其實就是 Bayes theorem 的改寫。它把「在功能 \(F\) 下看到第一個 action」, 改寫成「看到第一個 action 後,功能 \(F\) 有多可能」。
2. 再處理後面的 actions
對第 \(i\) 個 action,論文用: \[ p(A_i \mid A_{i-1},F) = \frac{ p(F \mid A_i,A_{i-1})p(A_i \mid A_{i-1}) } {p(F \mid A_{i-1})} \] 這代表:目前 action \(A_i\) 是否支持功能 \(F\),要看 「看到前一步 + 目前 action 後的功能可信度」相對於「只看到前一步時的功能可信度」有沒有增加。
3. 為什麼出現 \(\beta(A)\)?
整理過程中會出現一些只跟 action 本身有關、但跟候選功能 \(F\) 無關的項目, 例如 \(p(A_i \mid A_{i-1})\)。作者把這些項目合併成 \(\beta(A)\)。
因為最後要比較的是「哪個 \(F\) 最大」,只依賴 action、和 \(F\) 無關的項目不會影響排名, 所以可以在 \(\arg\max\) 裡忽略。
4. 乘法變加法
式 (4) 是一串機率相乘: \[ \beta(A)p(F \mid A_1) \prod_{i=2}^{N} \frac{p(F \mid A_i,A_{i-1})}{p(F \mid A_{i-1})} \] 取 log 後,乘法會變成加法,比例會變成相減: \[ \log p(F \mid A_i,A_{i-1})-\log p(F \mid A_{i-1}) \]
5. \(\arg\max_F\) 在做什麼?
它在所有候選功能 \(F\) 裡面,找出分數最高的那個。 \(\arg\max_F\) 的意思就是「讓後面分數最大的 \(F\)」。
6. 第一項
\[ \log p(F \mid A_i,A_{i-1}) \] 意思是:同時看到前一步 action 和目前 action 後,功能 \(F\) 有多可信。
7. 第二項
\[ \log p(F \mid A_{i-1}) \] 意思是:只看到前一步 action 時,功能 \(F\) 有多可信。
8. 兩者相減
相減後得到的是「目前 action 額外增加了多少證據」。 如果加入目前 action 後,某功能變得更明確,分數就會上升。
9. 為什麼要加總?
\(\sum_{i=1}^{N}\) 代表對 action chain 裡每一步都做這件事。 最後總分最高的功能,就是最能解釋整條 action chain 的功能。
核心重點:這個公式在算「每一步 action 對某功能的新增支持度」,最後選出最被整條 action chain 支持的功能。
Rank Score
Rank score:LLM 排越前面,代表越可能是真功能
\[
rank\_score(r)=\log((1-p)^{r-1}p)
\]
白話版
LLM 會列出它認為可能的功能。排名第 1 的功能給最高分,排名越後面分數越低。 \(p\) 越大,第一名和後面名次的差距越明顯。
詳解版:rank score 為什麼用幾何分布?
1. 問題:LLM 不一定給機率
專有 LLM 通常不會直接告訴你「這個功能的機率是 0.73」。 所以作者讓 LLM 輸出一個排序清單,再把排序轉成分數。
2. 排名轉機率
\[ (1-p)^{r-1}p \] 是第 \(r\) 名的機率。第 1 名是 \(p\),第 2 名是 \((1-p)p\),第 3 名是 \((1-p)^2p\)。
3. 為什麼取 log?
前面的 feature scoring 會把多個步驟的證據加總。 機率相乘在 log 空間會變成加法,因此比較方便累積分數。
4. \(p=0.5\) 的直覺
如果 \(p=0.5\),第 1 名是 0.5,第 2 名是 0.25,第 3 名是 0.125。 排名越後面,分數越低,但不是直接歸零。
核心重點:rank score 是把 LLM 的「排序」轉成可加總的數值證據。
Score Update
Score update:做完這個 action 後,功能更可信了嗎?
\[
score\_update(F_{jk}) =
rank\_score(F_{jk} \mid A_{ij}; A_i)
-
rank\_score(F_{jk} \mid A_i)
\tag{8}
\]
白話版
如果只看前一步 action 還不確定某功能存在,但看完「前一步 + 目前 action」後, LLM 更相信這個功能存在,那這個功能的分數就會上升。
例子
只看到「點商品」時,可能是查看詳情、加入購物車或評論商品。接著看到「Add to Cart」, 「加入購物車」這個功能的可信度就大幅增加。
詳解版:Score update 如何把 LLM 排名變成 FD 裡的分數?
這個公式在算什麼?
它在算「目前 action \(A_{ij}\) 對功能 \(F_{jk}\) 的額外支持度」。 如果看到目前 action 後,LLM 更確定某功能存在,這個功能在 Feature Database 裡的分數就會增加。
1. \(F_{jk}\) 是什麼?
在狀態 \(S_i\) 裡有很多可執行 actions。 \(A_{ij}\) 表示第 \(i\) 個狀態裡第 \(j\) 個 action。 LLM 會針對這個 action 推論一組可能功能: \[ \{F_{j1},F_{j2},\ldots\} \] 其中 \(F_{jk}\) 就是和 \(A_{ij}\) 關聯的第 \(k\) 個候選功能。
2. 第一項:看目前 action + 前文
\[ rank\_score(F_{jk} \mid A_{ij};A_i) \] 表示 LLM 在同時考慮目前 action \(A_{ij}\) 和前面的 action context \(A_i\) 時, 給功能 \(F_{jk}\) 的排名分數。
分號可以理解成「目前 action 搭配前文」。它不是一般機率符號的重點, 重點是作者把「只看前文」和「前文 + 目前 action」分開比較。
3. 第二項:只看前文
\[ rank\_score(F_{jk} \mid A_i) \] 表示只看前一步或目前狀態脈絡時,LLM 對同一功能的排名分數。
4. 兩者相減代表新增證據
\[ score\_update = \text{新脈絡分數} - \text{舊脈絡分數} \] 如果差值是正的,代表目前 action 讓這個功能更可信; 如果差值不高,代表目前 action 對這個功能沒有提供太多新證據。
5. 如果某功能只出現在新排名,舊排名沒有怎麼辦?
論文說:如果 \(F_{jk}\) 出現在 LLM 對 \((A_{ij},A_i)\) 的推論中, 但沒有出現在只看 \(A_i\) 的推論中,就用式 (7) 的固定低分補上: \[ rank\_score(r \mid r > R)=R\log(1-p)+\log(p) \tag{7} \]
這表示:沒有排進前 \(R\) 名,不代表機率是 0,而是給一個「排名很後面」的低分。
6. 分數更新到哪裡?
更新後的分數會寫回 Feature Database(FD)中對應的功能項目。 Action-Feature Database(AFD)則記錄「哪個 action 支持哪個 feature」以及該次排名分數。
7. 完整例子
假設只看前文「點選商品」時,LLM 沒有把「加入購物車」排進前 5 名, 所以它拿到式 (7) 的低分。接著看到目前 action 是「Add to Cart」, LLM 把「加入購物車」排第 1 名。兩者相減後,score update 很大, FD 裡「加入購物車」這個功能的 confidence score 就會上升。
核心重點:Score update 是 AUTOE2E 把 LLM 的局部判斷累積成全域 feature confidence 的機制。
Interactive Example
自己算一次 Feature Coverage
勾選每個 test 覆蓋到的功能。只要某個功能至少被一個 test 覆蓋,就會被計入分子。
被覆蓋功能
0 / 50%
目前沒有功能被測試案例覆蓋。
作者如何避免 LLM 亂寫 test?
1. 實際執行
產生的是 Selenium tests,必須真的跑在 web app 上。流程走不通就不會形成有效覆蓋。
2. Action logging
作者在 app 前端插樁,記錄 click、hover、input、select 等真實 UI actions。
3. Feature grammar
每個功能都有人工建立的 action grammar。test 的 action log 符合 grammar,才算 cover 到功能。
4. 量化承認錯誤
Precision 是 0.55,代表它不是保證全對,而是用 benchmark 衡量哪些 test 真正有效。